

IBM SPSSとは
IBM SPSS Statistics は、統計解析の初心者からプロフェッショナルまであらゆるニーズに応える統計解析のスタンダード・ソフトウェアです。1968 年 にスタンフォード大学の学生たちによって、米国大統領選挙の浮動票を予測するために誕生した SPSS は、社会学や心理学、教育学などの社会科学の分野をはじめ、医学・看護・保健・薬学などの医療分野、消費者行動学や商品開発などのマーケティング分野とさまざまな分野での研究や論文の作成、また授業などでの人材教育に活用されています。
実績に基づいた信頼性
発売開始から 50 年以上、現在も新しい機能を取り込みながら進化し続けています。論文作成に必要な機能要件を備え、世界中の多くの研究者や学生に利用されています。これまで数多くの論文に SPSS による分析の結果が掲載されています。
コマンド不要の高い操作性
複雑な分析手法もメニューの中から適用したい手法を選び、必要な項目を設定しボタンを押すだけで完了します。
統計解析でよく使う多くの検定や多変量解析の手法を分析メニューに実装しているので、複雑で難解な関数入力やプログラミングの手間はいりません。医療統計によく利用されるロジスティック回帰と傾向スコアや生存分析のカプラン・マイヤー法、Cox 回帰の比例ハザードモデルも実行可能です(一部オプション製品が必要)
統計解析でよく使う多くの検定や多変量解析の手法を分析メニューに実装しているので、複雑で難解な関数入力やプログラミングの手間はいりません。医療統計によく利用されるロジスティック回帰と傾向スコアや生存分析のカプラン・マイヤー法、Cox 回帰の比例ハザードモデルも実行可能です(一部オプション製品が必要)
見易い出力結果と論文などでの活用を想定した柔軟性
分析結果の表はピボットテーブルで出力されるので、注目したいポイントに合わせて行・列・層の項目の入れ替えが簡単に行えます。強調したいセルのフォントを変えたり、色を変えたりすることもできます。表のフォーマットには数多くのテンプレートがありアカデミック用のテンプレートも用意されています。また、一部の分析は実行時に、論文に適した APA* 形式を選択することができます。豊富に取り揃えられたグラフもテンプレートや編集機能が充実しています。さらに表、グラフともに MS Office と連携することで幅広い加工や修正が可能になります。
基本ソフト
詳細を見る >
IBM SPSS STATISTICS BASE
IBM SPSS Statisticsのソフトウェア構成の基本となるソフト。基本分析はもちろん、様々なオプションソフトを追加することで必要な分析機能を付加できます。
オプションソフト
目的に応じて、様々なオプションを組み合わせてご利用いただけます。
分析の手法を増やす
分析の精度を高める
表示をグラフィカルに
分析の効率を上げる
BOOTSTRAPPING
分析と結果の精度を効率的に検証するなら
DATA PREPARATION
データ準備を自動化し、手間のかかる作業を削減
V27より、BOOTSTRAPPING 及び DATA PREPARATIONは基本ソフト
IBM
SPSS
Statistics Base に含まれるようになりました
予測の分析を行う
マーケティング分析を強化する
Amos
詳細を見る >
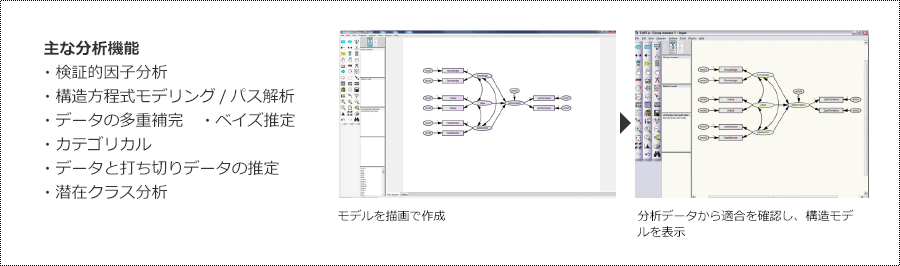
パス図をパレット上に描画し、そのまま分析することができるソフトウェア。
共分散構造分析
IBM SPSS AMOS
パス図をパレット上に描画し、そのまま分析することができるソフトウェア。
コマンドを入力せず、描画ツールを活用して、頭の中にあるモデルをそのまま画面に再現し、多数の候補からデータに最適な構造方程式を採用し分析することが可能です。
※ IBM SPSS AMOS は、IBM SPSS STATISTICS BASE をインストールしなくてもご利用いただけるソフトウェアです。
分析手法で選ぶSPSS製品
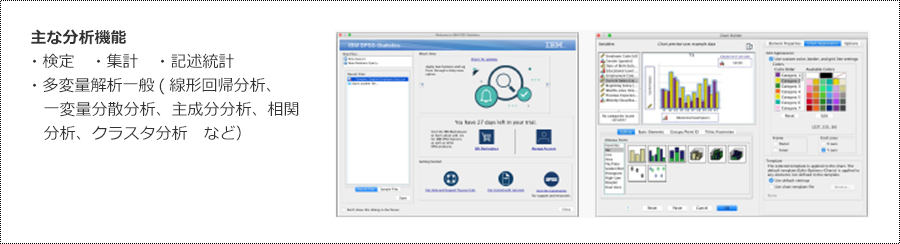
基礎集計・記述統計
度数分布表
度数分布表は、質的カテゴリデータのそれぞれの項目が、どれくらいの件数、度数があるのかを把握できる表のことを言います。質的データの記述統計において利用される代表的な表と言えます。
度数は英語でfrequencyまたはcountといいます。度数分布表はそのカテゴリの値が、どのくらい頻繁に出現するのか、その値の個数を表します。
度数分布表は棒グラフとともに表すことにより、より理解をすることが可能になります。アンケートでの満足度のデータや名義尺度のデータなどが対象となります。
<度数分布が可能なSPSS製品>
度数は英語でfrequencyまたはcountといいます。度数分布表はそのカテゴリの値が、どのくらい頻繁に出現するのか、その値の個数を表します。
度数分布表は棒グラフとともに表すことにより、より理解をすることが可能になります。アンケートでの満足度のデータや名義尺度のデータなどが対象となります。
<度数分布が可能なSPSS製品>
統計解析パッケージ「IBM SPSS Statistics Base」
50年以上の歴史を持つSPSS Statistics Baseは、度数分布表の作成も含め、記述統計、推測統計をカンタンに実行可能な統計解析のプラットフォームです。検定・集計関連
検定
検定とは、「集団Aは集団Bより平均身長が高い」というような仮説を立て、
その仮説が本当に正しいかどうかを統計的に検討するための手法であり、統計的仮説検定とも呼ばれます。一般的に統計による推測統計の一つで、英語では「test」と表記されます。推測統計は、手元にある標本(サンプル)と母集団との関係性を把握するための統計です。観測された標本に見られた差は偶然生じた差かもしれません。
そのため、観測された標本に見られた差が、偶然とは考えられないほど意味のある差であるか 母集団で比較しても本当に差があるといえるのかを統計的に検討する必要があります。
検定では、判断を下したい仮説を帰無仮説と対立仮説で記述します。
上記の例では、帰無仮説を「2つの集団の平均身長に差はない」とし、対立仮説を「2つの母集団の平均身長に差がある」とおきます。
統計的に差があると判断できる場合には帰無仮説を棄却し、「2つの母集団の平均身長に差がある」という対立仮説を採択し、
逆に、意味のある差はないと判断された場合、対立仮説を棄却し、帰無仮説を採択します。 なお、検定にはt検定、F検定、カイ2乗検定など様々な検定があります。
なお、SPSS Statisticsでは、各種検定手法を搭載しています。
<検定におすすめのSPSS製品>
なお、SPSS Statisticsでは、各種検定手法を搭載しています。
<検定におすすめのSPSS製品>
IBM SPSS Statistics Base
統計解析のスタンダードツールIBM SPSS Statisticsは、さまざまな検定機能を標準装備しています。
t検定
t検定とは、2つの集団の平均に意味のある差があるのかどうかの検定です。
t検定には「対応がある場合」と「対応がない場合」の2つの手順があります。「対応がある場合」とは、例えば夏期講習の前後でテストの点数が上がったかどうかの検定などです。
夏期講習の前と後で同じ生徒の点数に注目するので、個々の生徒の点数の変化を考える
必要があります。一方、「対応がない場合」とは、AクラスとBクラスでテストの点数に差があるかどうかの検定などです。
この場合AクラスとBクラスに人の対応はないので、対応を考える必要はありません。SPSS
Statisticsでは、t検定を簡単にメニューから実行することが可能です。
<t検定におすすめのSPSS製品>
<t検定におすすめのSPSS製品>
IBM SPSS Statistics Base
統計解析のスタンダードツール IBM SPSS Statisticsは、t検定もメニューから簡単に分析が可能です。
クロス集計
クロス集計とは、アンケートでよく使われる手法で、2つ以上の質的なデータの関係性を調べるための集計方法です。1つの項目を縦軸に、もう1つの項目を横軸に配置し、項目間の関係を明らかにします。
<クロス集計におすすめのSPSS製品>
<クロス集計におすすめのSPSS製品>
IBM SPSS Statistics Base
統計解析のスタンダードツール IBM SPSS Statisticsは、クロス集計もメニューから簡単作成IBM SPSS Custom Tables
複雑なクロス集計もウィザード形式により容易に作成可能なIBM SPSS Statisticsのオプション製品。
正確確率検定
正確確率検定とは、標本数が少ない場合に、2変数の独立性の検定に用いられ、2×2分割表の2変数の間に有意な差が見られるかを検討します。標本数が多い場合にはカイ2乗分布が用いられますが、標本数が少ない場合や、偏りの大きいデータの場合には、
カイ2乗検定は適さないため、正確確率検定が用いられます。
<正確確率検定におすすめのSPSS製品>
<正確確率検定におすすめのSPSS製品>
IBM SPSS Statistics Base
統計解析のスタンダードツールIBM SPSS Statisticsは、さまざまな検定機能を標準装備しています。IBM SPSS Exact Tests
正確確率検定をはじめ、ピアソンのカイ2乗検定、尤度比検定などに対応のIBM SPSS Statisticsオプション。統計解析手法
重回帰分析/回帰分析
回帰分析は、統計解析手法の中でも良く知られている分析手法のひとつです。
回帰分析は、説明変数から目的変数を推定する分析手法であり、予測や制御のために用いられます。
2変数間の変動の傾向を数式により、実データとの誤差が最小になるようにモデル化を行います。
回帰分析というと主に単回帰分析を指し、変数間に直線式を当てはめます。また線型回帰・非線型回帰・ロジスティック回帰などさまざまな種類が存在します。
<回帰分析が可能なSPSS製品>
回帰分析は、説明変数から目的変数を推定する分析手法であり、予測や制御のために用いられます。
2変数間の変動の傾向を数式により、実データとの誤差が最小になるようにモデル化を行います。
回帰分析というと主に単回帰分析を指し、変数間に直線式を当てはめます。また線型回帰・非線型回帰・ロジスティック回帰などさまざまな種類が存在します。
<回帰分析が可能なSPSS製品>
IBM SPSS Statistics Base
適合度や回帰係数などの回帰分析に関する統計量を出力します。ステップワイズ法により独立変数の選択が可能です。IBM SPSS Regression
非線型による回帰分析が可能です。ロジステック回帰分析を行うことができます。IBM SPSS Advanced Statistics
従属変数に順序尺度をもつロジスティック回帰分析が可能です。IBM SPSS Categories
データに質的尺度を持つ変数による回帰分析が可能です。
ロジスティック回帰
回帰分析には線型回帰・非線型回帰・ロジスティック回帰などさまざまな種類があります。 ロジスティック回帰は、注目する結果が、比率や2値データで得られるとき、
その結果を予測したり、結果にいたる要因を探索したりするのに適した手法です。
<ロジスティック回帰分析に対応しているSPSS製品>
<ロジスティック回帰分析に対応しているSPSS製品>
IBM SPSS Statistics Base
使いやすさ、解りやすさを追求した統計解析ソフトのスタンダード。統計解析ソフトIBM SPSS Statistics の基本ソフトウェアです。IBM SPSS Regression
複数の値をもつ名義尺度のデータを従属変数とするロジスティック回帰分析を行うことができます。オッズ比などの統計量を出力します。IBM SPSS Advanced Statistics
Statistics Base オプションから、一般線型モデルや対数線型分析など、高度なモデリングオプションを適用することができます。
ノンパラメトリック検定
ノンパラメトリック検定とは、母集団に分布の仮定を必要としない検定のことをいいます。
例えば、t検定では、母集団に正規性を仮定しますが、ノンパラメトリックな検定ではそのような仮定を設けません。 ノンパラメトリックな検定は、標本数が少ない場合にも有効です。
また、名義尺度や順序尺度のデータについても処理することができます。
しかし、どんな場合でもノンパラメトリックな検定を用いたほうがよいわけではありません。 パラメトリックな手法を適用できる条件がそろっている場合には、ノンパラメトリックな検定は検出力が低下するため、 パラメトリックな手法を用いたほうが妥当です。
<ノンパラメトリック検定が可能なSPSS製品>
しかし、どんな場合でもノンパラメトリックな検定を用いたほうがよいわけではありません。 パラメトリックな手法を適用できる条件がそろっている場合には、ノンパラメトリックな検定は検出力が低下するため、 パラメトリックな手法を用いたほうが妥当です。
<ノンパラメトリック検定が可能なSPSS製品>
IBM SPSS Statistics Base
統計解析のスタンダードツールIBM SPSS Statisticsは、さまざまな検定機能を標準装備しています。
ベイズ推定
ベイズ推定とは、観測された事実を基にして、その事実の原因となる事象が起こる確率を推定する方法です。
これは、観測者がその事象が起こると考える確率(事前確率)を、その後に観測された事実によって、 より客観的な確率(事後確率)に推定していく方法です。
さらに新しい事実が得られたなら、求めた事後確率を事前確率と考え、新しい事実に基づいて推定を行うことで、 さらに客観的な確率を求めることができます。
統計学では、ベイズ推定が応用されて、ベイズ統計学の代表的な方法になっています。
<ベイズ推定に対応しているSPSS製品>
※当製品は、IBM SPSS Statistics Base なしでも稼動します。
これは、観測者がその事象が起こると考える確率(事前確率)を、その後に観測された事実によって、 より客観的な確率(事後確率)に推定していく方法です。
さらに新しい事実が得られたなら、求めた事後確率を事前確率と考え、新しい事実に基づいて推定を行うことで、 さらに客観的な確率を求めることができます。
統計学では、ベイズ推定が応用されて、ベイズ統計学の代表的な方法になっています。
<ベイズ推定に対応しているSPSS製品>
IBM SPSS Amos
パス図をイメージして共分散構造分析を行うことができます。 探索的にモデルをシュミレーションさせたり、多母集団の比較などを行うことができます。※当製品は、IBM SPSS Statistics Base なしでも稼動します。
一般線型モデル
一般線型モデル(General Linear Model)とは、目的変数が複数の説明変数の線型結合で表される式のことです。
線型モデル、重回帰モデル、分散分析モデル、共分散モデルをまとめて一般線型モデルと呼びます。
<一般線型モデルに対応しているSPSS製品>
線型モデル、重回帰モデル、分散分析モデル、共分散モデルをまとめて一般線型モデルと呼びます。
<一般線型モデルに対応しているSPSS製品>
IBM SPSS Statistics Base
使いやすさ、解りやすさを追求した統計解析ソフトのスタンダード。統計解析ソフトIBM SPSS Statisticsの基本ソフトウェアです。IBM SPSS Advanced Statistics
多変量、反復測定の場合の分散分析を行うことができます。その後の検定や球面性の検定などを行うことができます。GLM一般線型モデル(GLM)を搭載したIBM SPSS Statisticsオプション製品。
分散分析(ANOVA)
分散分析(ANOVA)は、2つ以上のあるグループ間に差があるのかを明らかにする分析手法です。
主に実験の分析において、母集団の平均を同じと考えてよいのかどうかを決定するのに使用されます。 グループを識別する要素が1つの場合を一元配置分散分析と呼び、2つまたは3つ以上の場合をそれぞれ二元配置分散分析、多元配置分散分析と呼びます。
二元配置分散分析、多元配置分散分析では、要素間の交互作用も検討する必要があります。
分散分析(ANOVA)の活用例
・薬剤の時間と量を変えたときの細胞分裂の差(医薬統計)
・品質管理
・学力調査
<分散分析(ANOVA)に対応しているSPSS製品>
※当製品は IBM SPSS Statistics Base なしでも稼動します。
主に実験の分析において、母集団の平均を同じと考えてよいのかどうかを決定するのに使用されます。 グループを識別する要素が1つの場合を一元配置分散分析と呼び、2つまたは3つ以上の場合をそれぞれ二元配置分散分析、多元配置分散分析と呼びます。
二元配置分散分析、多元配置分散分析では、要素間の交互作用も検討する必要があります。
分散分析(ANOVA)の活用例
・薬剤の時間と量を変えたときの細胞分裂の差(医薬統計)
・品質管理
・学力調査
<分散分析(ANOVA)に対応しているSPSS製品>
IBM SPSS Statistics Base
統計解析ソフトIBM SPSS Statisticsの基本ソフトウェア。グループ間の比較を行います。その後の検定を行い、ペアごとの差の検定も行うことができます。等分散の検定を行うことができます。IBM SPSS Advanced Statistics
多元配置、多変量による分散分析ができるIBM SPSS Statisticsのアドオンオプション。反復測定による分散分析も可能です。IBM SPSS Amos
共分散構造分析のパス図による分散分析モデルを行うことができます。※当製品は IBM SPSS Statistics Base なしでも稼動します。
時系列分析
時系列分析の目的は、時間の経過に沿って記録した時系列データを用いて、 現在までに得られた情報から、今後の変動の予測・制御を行うことです。
時系列データに含まれる、季節変動や不規則変動などの変動を分析します。
時系列分析の活用例
・株価の予測
・売上の予測
<時系列分析が可能なSPSS製品>
時系列分析の活用例
・株価の予測
・売上の予測
<時系列分析が可能なSPSS製品>
IBM SPSS Statistics Base
使いやすさ、解りやすさを追求した統計解析ソフトのスタンダード。統計解析ソフトIBM SPSS Statisticsの基本ソフトウェアです。IBM SPSS Forecasting
時系列データ分析において、予測精度の向上を可能にするパワフルツール。
プロビット分析
プロビット分析とは、重回帰分析において被説明変数をダミー変数(0と1など)に置き換えて
各説明変数の影響を調べる場合に用いられる手法です。つまり、被説明変数が一方(0か1など)になる確率が、他の説明変数の影響を受けているかを分析することができます。ロジット分析との違いは確率推定関数であり、ロジット分析がロジスティック関数を用いるのに対して、
プロビット分析は正規累積関数を用います。推定関数は、最尤推定法によって求めます。
<プロビット分析に対応しているSPSS製品>
<プロビット分析に対応しているSPSS製品>
IBM SPSS Statistics Base
使いやすさ、解りやすさを追求した統計解析ソフトのスタンダード。統計解析ソフトIBM SPSS Statisticsの基本ソフトウェアです。IBM SPSS Regression
ロジスティック回帰、非線型回帰、プロビット分析など、専門的な回帰分析手法をカバーしたオプション。
コレスポンデンス分析
コレスポンデンス分析は、ブランドマップなどによく利用される統計手法です。
名義尺度の2変数のクロス集計表を作成し、マップを作成することで項目間の関係性をみることが可能です。
数量化Ⅲ類と類似している分析手法です。
<コレスポンデンス分析が可能なSPSS製品>
<コレスポンデンス分析が可能なSPSS製品>
IBM SPSS Statistics Base
適合度や回帰係数などの回帰分析に関する統計量を出力します。ステップワイズ法により独立変数の選択が可能です。IBM SPSS Categories
データに質的尺度を持つ変数による回帰分析が可能です。
パス解析
パス解析とは、パス図を用いて変数間の関係を明らかにするための分析です。パス図とは変数間の因果関係や相関関係を矢印で表した図です。
重回帰分析では各説明変数から目的変数への因果関係のみを仮定するのに対し、 パス解析では、変数間に自由に因果関係を仮定して、より複雑なモデルを分析することができます。
<パス解析に対応しているSPSS製品>
※当製品は IBM SPSS Statistics Base なしでも稼動します。
重回帰分析では各説明変数から目的変数への因果関係のみを仮定するのに対し、 パス解析では、変数間に自由に因果関係を仮定して、より複雑なモデルを分析することができます。
<パス解析に対応しているSPSS製品>
IBM SPSS Amos
共分散構造分析のパス図による分散分析モデルを行うことができます。※当製品は IBM SPSS Statistics Base なしでも稼動します。
クラスター分析
データ間の距離(類似度・非類似度)から互いに似たものを集めクラスターを作り、データを分類する手法(の総称)であり、
データを外的基準なしに自動的、定量的に分類できます。
クラスター分析の活用例
アカデミック
・ブランドの分類
・消費者のセグメンテーション
ビジネス
・ブランドの分類
・アンケート調査におけるイメージワードの分類
・顧客のセグメンテーション
<クラスター分析が可能なSPSS製品>
クラスター分析の活用例
アカデミック
・ブランドの分類
・消費者のセグメンテーション
ビジネス
・ブランドの分類
・アンケート調査におけるイメージワードの分類
・顧客のセグメンテーション
<クラスター分析が可能なSPSS製品>
IBM SPSS Statistics Base
使いやすさ、解りやすさを追求した統計解析ソフトのスタンダード。統計解析ソフトIBM SPSS Statisticsの基本ソフトウェアです。
相関分析
相関分析とは、2つの変数間の関連を明らかにする分析です。
例えば、国語と数学のテストの点数に関連があるか調べるために、散布図を作ったり、相関係数を求めたりします。
一方が大きくなると、もう一方も大きくなる関係を「正の相関がある」といい、 一方が大きくなるともう一方が小さくなる関係を「負の相関がある」といいます。
相関関係の程度を示す相関係数は-1~1の値をとり、絶対値が1に近いほど関係が強いといえます。
相関分析の活用例
・年齢とコレステロールの相関係数が0.78の場合、正の相関があると判断し、それらの間に関係性があることが分かります。
・1日のビールの販売数と気温の相関係数が0.78の場合、正の相関があると判断し、それらの間に関係性があることが分かります。
<相関分析に対応しているSPSS製品>
例えば、国語と数学のテストの点数に関連があるか調べるために、散布図を作ったり、相関係数を求めたりします。
一方が大きくなると、もう一方も大きくなる関係を「正の相関がある」といい、 一方が大きくなるともう一方が小さくなる関係を「負の相関がある」といいます。
相関関係の程度を示す相関係数は-1~1の値をとり、絶対値が1に近いほど関係が強いといえます。
相関分析の活用例
・年齢とコレステロールの相関係数が0.78の場合、正の相関があると判断し、それらの間に関係性があることが分かります。
・1日のビールの販売数と気温の相関係数が0.78の場合、正の相関があると判断し、それらの間に関係性があることが分かります。
<相関分析に対応しているSPSS製品>
IBM SPSS Statistics Base
相関係数、有意性の検定をします。順序尺度による相関係数も算出します。 使いやすさ、解りやすさを追求した統計解析ソフトのスタンダード。
因子分析
因子分析はデータを要約するために用いる手法であり、変数間の相関関係から潜在的ないくつかの共通因子を発見・抽出し、データ(変数群)を潜在因子に分解します。
主成分分析は主成分にデータを結合しますが、因子分析はデータを因子に分解します。また、主成分分析では誤差を認めないあるいは誤差を含んで分析するのに対し、因子分析では誤差を独自因子として分析します。
因子分析の活用例
アカデミック
・学習効果の測定
・心理評価
・アンケート分析
・大規模データの要約 ビジネス
ビジネス
・市場調査分析(アンケート)
・大規模データの要約
<因子分析が可能なSPSS製品>
因子分析の活用例
アカデミック
・学習効果の測定
・心理評価
・アンケート分析
・大規模データの要約 ビジネス
ビジネス
・市場調査分析(アンケート)
・大規模データの要約
<因子分析が可能なSPSS製品>
IBM SPSS Statistics Base
使いやすさ、解りやすさを追求した統計解析ソフトのスタンダード。統計解析ソフトIBM SPSS Statisticsの基本ソフトウェアです。
欠損値分析
欠損のあるデータを分析しようとすると、データ数の減少などから分析の精度が落ちる場合があります。
そこで、欠損データに対して、他の変数を利用して欠損部分の予測、置き換えを行うものが欠損値分析です。
欠損データの予測には、観測されたデータから重回帰式を求めて予測する方法や、最尤推定値を求めるアルゴリズムを用います。
<欠損値分析に対応しているSPSS製品>
そこで、欠損データに対して、他の変数を利用して欠損部分の予測、置き換えを行うものが欠損値分析です。
欠損データの予測には、観測されたデータから重回帰式を求めて予測する方法や、最尤推定値を求めるアルゴリズムを用います。
<欠損値分析に対応しているSPSS製品>
IBM SPSS Statistics Base
使いやすさ、解りやすさを追求した統計解析ソフトのスタンダード。統計解析ソフトIBM SPSS Statisticsの基本ソフトウェアです。IBM SPSS Missing Values
新データ内にある欠損情報に対して、EM法や回帰手法を使用してデータの置き換えを行います。IBM SPSS Advanced Statistics
従属変数に順序尺度をもつロジスティック回帰分析が可能です。
主成分分析
主成分分析は、多数の変数を少数の合成変数(主成分)に縮約し、データの解釈を容易にするための手法です。
主成分は、持っている情報量の順に第1主成分、第2主成分、…となり、データの持つ変数の数だけ求まりますが、 一般に累積寄与率が0.8を超えるまでの主成分を用います。
主成分分析の活用例
・アンケート分析
・スポーツチームの分析
<主成分分析が可能なSPSS製品>
主成分は、持っている情報量の順に第1主成分、第2主成分、…となり、データの持つ変数の数だけ求まりますが、 一般に累積寄与率が0.8を超えるまでの主成分を用います。
主成分分析の活用例
・アンケート分析
・スポーツチームの分析
<主成分分析が可能なSPSS製品>
IBM SPSS Statistics Base
使いやすさ、解りやすさを追求した統計解析ソフトのスタンダード。統計解析ソフトIBM SPSS Statisticsの基本ソフトウェアです。IBM SPSS Categories
データに質的尺度を持つ変数による回帰分析が可能です。
共分散構造分析
共分散構造分析は、観測変数から直接観測できない潜在変数を導出し、潜在変数と観測変数との間の因果関係を理解するための統計的アプローチです。
潜在変数と観測変数の因果関係を分析できる点から、回帰分析と因子分析を組み合わせた分析手法と考えることができます。 各種の社会現象・自然現象などの因果関係を調べるために用いられます。
共分散構造分析の活用例
・アレルギー疾患調査などの医薬統計
・ブランドイメージの計量化
・消費者行動における潜在意識調査
<共分散構造分析に対応しているSPSS製品>
※当製品は IBM SPSS Statistics Base なしでも稼動します。
潜在変数と観測変数の因果関係を分析できる点から、回帰分析と因子分析を組み合わせた分析手法と考えることができます。 各種の社会現象・自然現象などの因果関係を調べるために用いられます。
共分散構造分析の活用例
・アレルギー疾患調査などの医薬統計
・ブランドイメージの計量化
・消費者行動における潜在意識調査
<共分散構造分析に対応しているSPSS製品>
IBM SPSS Statistics Base
使いやすさ、解りやすさを追求した統計解析ソフトのスタンダード。統計解析ソフトIBM SPSS Statisticsの基本ソフトウェアです。IBM SPSS Amos
パス図をイメージして共分散構造分析を行うことができます。探索的にモデルをシュミレーションさせたり、多母集団の比較などを行うことができます。※当製品は IBM SPSS Statistics Base なしでも稼動します。
コンジョイント分析
製品を構成する要因(属性)と各要因に対する具体的な水準を設定し、製品案を複数用意した上で、
アンケートにより回答者に製品案を評価してもらい、消費者のスペックに対する選好度を推定する調査・分析手法です。
コンジョイント分析では、消費者の嗜好を理解することで、製品の属性の重要性と、その属性の最適な水準を見つけ出すことを目的とし、 新商品開発戦略・マーケティング戦略の立案に用います。
コンジョイント分析の活用例
アカデミック
・製品の価格評価
・生産/品質管理
ビジネス
・(新)製品企画と価格決定
・各属性の価格評価
<コンジョイント分析が可能なSPSS製品>
コンジョイント分析では、消費者の嗜好を理解することで、製品の属性の重要性と、その属性の最適な水準を見つけ出すことを目的とし、 新商品開発戦略・マーケティング戦略の立案に用います。
コンジョイント分析の活用例
アカデミック
・製品の価格評価
・生産/品質管理
ビジネス
・(新)製品企画と価格決定
・各属性の価格評価
<コンジョイント分析が可能なSPSS製品>
IBM SPSS Statistics Base
適合度や回帰係数などの回帰分析に関する統計量を出力します。ステップワイズ法により独立変数の選択が可能です。IBM SPSS Conjoint
顧客の嗜好をより理解し、最適なマーケティングを支援するコンジョイント分析用 オプション。
生存分析
生存分析とは、対象とする2つのイベント(観察開始時点と発病・死亡など)の間の経過時間に基づくデータの評価に用いる手法です。例えば、ある治療の効果を分析したいときに、病気の治療を行った患者において、
病気が再発する(イベント)までの時間を解析するという方法のことです。
イベントが再発であっても治癒であっても、単に率を調べるのではなく、 時間の経過の中でどのくらいの割合の患者に起こるのかが問題となります。そのため、イベントの累積発生率をプロットした生存曲線を使って分析を行います。
生存分析の活用例
・薬剤の効果の評価
・クレジットカード会員が1年後に解約する確率を、性別や年齢、年収などの属性データや利用履歴から予測できます。
<生存分析に対応しているSPSS製品>
イベントが再発であっても治癒であっても、単に率を調べるのではなく、 時間の経過の中でどのくらいの割合の患者に起こるのかが問題となります。そのため、イベントの累積発生率をプロットした生存曲線を使って分析を行います。
生存分析の活用例
・薬剤の効果の評価
・クレジットカード会員が1年後に解約する確率を、性別や年齢、年収などの属性データや利用履歴から予測できます。
<生存分析に対応しているSPSS製品>
IBM SPSS Statistics Base
使いやすさ、解りやすさを追求した統計解析ソフトのスタンダード。統計解析ソフトIBM SPSS Statisticsの基本ソフトウェアです。IBM SPSS Advanced Statistics
生存表、生存確率が算出でき、性別などの属性間の比較をグラフで表示できます。
信頼性分析
アンケートデータ等の尺度や項目の信頼性を調べ、信頼性を高めるための分析方法です。
よく分析に用いられるものに、値が大きければ信頼性が高いとするアルファ係数があります。
「信頼性がある」というのは、尺度内の項目同士に一貫性があることです。
アンケートの回答者が、同じ尺度内の項目に対して同じような回答(YesやNo)をしていればアルファ係数は大きくなり、 回答のバラツキが大きければアルファ係数は小さくなります。
もし、尺度内の項目と方向性の異なる項目があれば、その項目を削除することで、アルファ係数を大きくすることができ、信頼性を高めることができます。
信頼性分析の活用例
・アンケート項目の検討
<対応IBM SPSS製品>
よく分析に用いられるものに、値が大きければ信頼性が高いとするアルファ係数があります。
「信頼性がある」というのは、尺度内の項目同士に一貫性があることです。
アンケートの回答者が、同じ尺度内の項目に対して同じような回答(YesやNo)をしていればアルファ係数は大きくなり、 回答のバラツキが大きければアルファ係数は小さくなります。
もし、尺度内の項目と方向性の異なる項目があれば、その項目を削除することで、アルファ係数を大きくすることができ、信頼性を高めることができます。
信頼性分析の活用例
・アンケート項目の検討
<対応IBM SPSS製品>
IBM SPSS Statistics Base
調査データなどの項目尺度の信頼性を分析します。アルファ係数やGuttman、 級内相関係数を算出します。使いやすさ、解りやすさを追求した統計解析ソフトのスタンダード。統計解析ソフトIBM SPSS Statistics の基本ソフトウェアです。IBM SPSS Missing Values
新データ内にある欠損情報に対して、EM法や回帰手法を使用してデータの置き換えを行います。
ロジット対数線型分析
ロジット対数線型分析とは、対数線型モデルに基づいたロジット分析のことです。
対数線型モデルとは、2変数以上のクロス表において、クロス表のある要素が起こる確率を求める式の両辺を、
対数をとることで線型モデルにしたものです。
対数線型モデルでは、クロス表のある要素が起こる確率が、他の要素が起こる確率の何倍であるかを求めることができます。 対数線型モデルでは、従属変数と独立変数の区別がないのですが、ある変数を従属変数、その他の変数を独立変数として分析を行うのがロジット分析です。
また、重回帰分析では従属変数と独立変数は量的変数ですが、ロジット分析では、従属変数と独立変数が質的変数(0と1の変数)の場合の分析手法です。
<ロジット対数線型分析を実現するSPSS製品>
対数線型モデルでは、クロス表のある要素が起こる確率が、他の要素が起こる確率の何倍であるかを求めることができます。 対数線型モデルでは、従属変数と独立変数の区別がないのですが、ある変数を従属変数、その他の変数を独立変数として分析を行うのがロジット分析です。
また、重回帰分析では従属変数と独立変数は量的変数ですが、ロジット分析では、従属変数と独立変数が質的変数(0と1の変数)の場合の分析手法です。
<ロジット対数線型分析を実現するSPSS製品>
IBM SPSS Statistics Base
対数線型モデルとロジットモデルを度数データに適合するIBM SPSS Statisticsのオプション製品。IBM SPSS Advanced Statistics
従属変数が順序尺度の場合のロジスティック回帰分析を行います。データマイニング手法
Two-Step
Two-Stepのアルゴリズムは、大量のケースをクラスタ化するためのもので、類似度の基準に基づいて観測値をグループ分けします。
Two-Stepクラスタ化方法では、最初のステップでクラスタ中心を発見するためにデータを流し 2番目のステップでは、階層クラスタ化方法を使用して、サブクラスタをより大きなクラスタに結合させていきます。Two-Stepクラスタリングには、学習データに最適なクラスタ数を自動的に推定するという利点があります。また、混在したフィールド型を処理でき、大規模なデータセットを効率よく扱うこともできます。
<Two-Stepが可能なSPSS製品>
国内実績No.1のデータマイニングツールです。
Two-Stepクラスタ化方法では、最初のステップでクラスタ中心を発見するためにデータを流し 2番目のステップでは、階層クラスタ化方法を使用して、サブクラスタをより大きなクラスタに結合させていきます。Two-Stepクラスタリングには、学習データに最適なクラスタ数を自動的に推定するという利点があります。また、混在したフィールド型を処理でき、大規模なデータセットを効率よく扱うこともできます。
<Two-Stepが可能なSPSS製品>
IBM SPSS Modeler
Two-Stepをはじめ、さまざまなデータマイニング手法と強力なデータ加工機能を搭載。国内実績No.1のデータマイニングツールです。
GRI
GRI とはGeneralized Rule
Inductionの略称で、データのアソシエーションルールを発見します。たとえば、顧客がひげそりとアフターシェーブローションを購入した場合、その顧客は高い確信度でシェービングクリームも購入します。
GRIは、ルールの一般性(範囲)と精度(確信度)の両方を考慮した指標を使用して、ルールと最大の情報内容を抽出します。GRIは、数値入力とカテゴリ入力を処理できますが、対象はカテゴリであることが必要です。
<GRIが可能なSPSS製品>
GRIは、ルールの一般性(範囲)と精度(確信度)の両方を考慮した指標を使用して、ルールと最大の情報内容を抽出します。GRIは、数値入力とカテゴリ入力を処理できますが、対象はカテゴリであることが必要です。
<GRIが可能なSPSS製品>
IBM SPSS Modeler
ビジュアルプログラミングの手法を用いることにより、データマイニングのプロセスを視覚的に捉え、高度で素早い分析環境を提供します。
Apriori(アプリオリ)
Aprioriは、データから関連性のあるルールを発見するためのアルゴリズムです。Aprioriは、比較的単純でメモリ消費量が少なく,かつ効率がよいという特徴を持っています。5種類のルール選択方法があり、大量のデータでも効率的にルールを発見することが可能で、大きな問題の場合は、たいていAprioriの方がGRI(Generalized
Rule Induction)よりも高速に学習できます。
保持できるルール数に特に制限はなく、また、最大32の前提条件を持つルールを処理できます。
Aprioriでは、入力フィールドと出力フィールドのどちらもシンボル型のデータしか扱えませんが、 両方で同じデータセットを扱っている場合には、より効率的かつ高速のパフォーマンスを実現できます。
<Aprioriを実現するSPSS製品>
国内800社に利用されている1データマイニングツールです。
保持できるルール数に特に制限はなく、また、最大32の前提条件を持つルールを処理できます。
Aprioriでは、入力フィールドと出力フィールドのどちらもシンボル型のデータしか扱えませんが、 両方で同じデータセットを扱っている場合には、より効率的かつ高速のパフォーマンスを実現できます。
<Aprioriを実現するSPSS製品>
IBM SPSS Modeler
Aprioriをはじめ、さまざまなデータマイニング手法と強力なデータ加工機能を搭載。国内800社に利用されている1データマイニングツールです。
決定木分析・デシジョンツリー
デシジョンツリー(決定木)とは、データ内のセグメント、パターン、階層関係を樹木の形で視覚的に表現したものです。
データマイニングにおけるデシジョンツリー分析は、 対象データ全体を最もよく分類できる変数を探索するアルゴリズムによって、データを分類していきます。
主なアルゴリズムにC&RT、C5.0、CHAIDなどがあります。
デシジョンツリーの活用例
・離反顧客の予測
<決定木に対応しているSPSS製品>
ゲインチャートやリフトチャートを作成します。
データマイニングにおけるデシジョンツリー分析は、 対象データ全体を最もよく分類できる変数を探索するアルゴリズムによって、データを分類していきます。
主なアルゴリズムにC&RT、C5.0、CHAIDなどがあります。
デシジョンツリーの活用例
・離反顧客の予測
<決定木に対応しているSPSS製品>
IBM SPSS Statistics Base
使いやすさ、解りやすさを追求した統計解析ソフトのスタンダード。統計解析ソフトIBM SPSS Statisticsの基本ソフトウェアです。IBM SPSS Decision Trees
CHAID、C&RT、QUESTなどを搭載するIBM SPSS Statisticsのアドオンオプション。IBM SPSS Modeler
判別やセグメントのルールを算出できます。ルールを元に予測結果を算出します。ゲインチャートやリフトチャートを作成します。