

2つのサービスを組み合わせ生成AIの可能性を広げる強力なツールに
生成AIの価値創出
ChatGPTでAIが一般的に普及し、テクノロジーとして成熟してくるとともに、企業や組織は、生成AIを社内の業務の効率化や、仕事の進め方における変革だけではなく、ビジネス上の利益や差別化、新しいイノベーションの促進といった価値創出に向けて、どのように生成AIを活用するか、そのニーズがますます強まってきます。
例えば、
- 消費者が必要とするサービスや製品の生成AIを活用した検索
- 生成AIを利用して、マーケティングコンテンツを生成、大規模なパーソナライゼーション
- 政府や自治体による住民サービスの向上、地域課題解決に向けての生成AIの活用
- 新製品や新サービスの開発プロセスの効率化
- 構造化・非構造化データを含む企業データ分析に生成AIを活用し、意思決定の改善やコスト削減を実現する
といったような活用シーンが考えられます。またこのような価値創出を目的とした生成AIを利用する中では、大規模なデータをリアルタイムに処理をする、また規模だけでなく、地理的に分散している、組織がより迅速にデータを処理することが求められるユースケースも考えられます。
今回の記事では、そのようなユースケースを実現しうるソリューションの組み合わせとして、Azure OpenAIとYugabyteDBで、拡張性の高い生成AIを実現する技術的連携手法をご紹介します。
YugabyteDBの特長については、過去の記事もご参照ください。
分散データベースとは何か?その特徴を解説
Azure OpenAIとYugabyteDBを使用した生成AIアプリケーションの構築の手順をご紹介
ここからは、実際にAzure OpenAIとYugabyteDBを使用した生成AIアプリケーションの構築を通じ、類似性検索を実行する方法をご説明します。一歩先の未来を歩むエンジニアのみなさまには、ぜひこの手順をハンズオンで実施いただけたらと思います。
前提
本記事は YugabyteDB に掲載されているブログ記事を参考にしています。
記事名:Build Scalable Generative AI Applications with Azure OpenAI and YugabyteDB
https://www.yugabyte.com/blog/build-generative-ai-low-latency/
(YugabyteDBのセットアップからアプリケーション起動方法まで網羅されています。オリジナル記事は特に言及していませんが、MacOS 環境を対象にしているように見受けました。万一、Windows環境に不慣れでしたらば MacOS や Linux 環境をご利用ください)
今回YugabyeDB は Ver.2.19オープンソース版を使用しました。最新版 Ver.2.20 でも動作することを確認済みです。
自習/検証用に Docker Engine は v24をWindows 11 Pro (64ビット, 23H2) 環境で使用しました。その他のコンポーネント条件は前述 YugabyteDB ブログ記事をご参照ください。
※セットアップ時に node コマンドが見つからないとWindows から反応があった場合はお手数ですが
https://nodejs.org/en/download こちらから 最新 node.js のMSI インストーラーを入手しインストールを終えてから再度セットアップをお願いいたします。
今回作成するサンプルアプリケーションについて
今回作成するAzure OpenAIモデルのデプロイサンプルアプリケーションは Airbnbを使ってサンフランシスコ旅行者向けの宿泊施設を推奨するサービスで、pgvector 拡張機能を使用して分散YugabyteDBクラスタ全体で類似性検索を実行する方法をハンズオンで自習する内容です。単にgitからのソースをデプロイするだけではなく、Azure OpenAI の挙動も理解することで応用スキルを高められる構成としています。
次のサービス アーキテクチャ図で示す通り、異なる2つのモードをサポートしています。
チャットモードは得られる回答提示が遅く、埋込モードは高速提示するものです。
- Azure OpenAIチャットモード:バックエンドプロセスが、Azure OpenAI GPTモデルの一つを利用して、ユーザーに推奨の宿泊施設を回答する
- YugabyteDB 埋め込みモード: バックエンドは Azure OpenAI 埋め込みモデルを使用して、ユーザーのプロンプトを埋め込み に変換し、YugabeyteDBの類似検索からユーザーのプロンプトに一致する宿泊施設を回答する
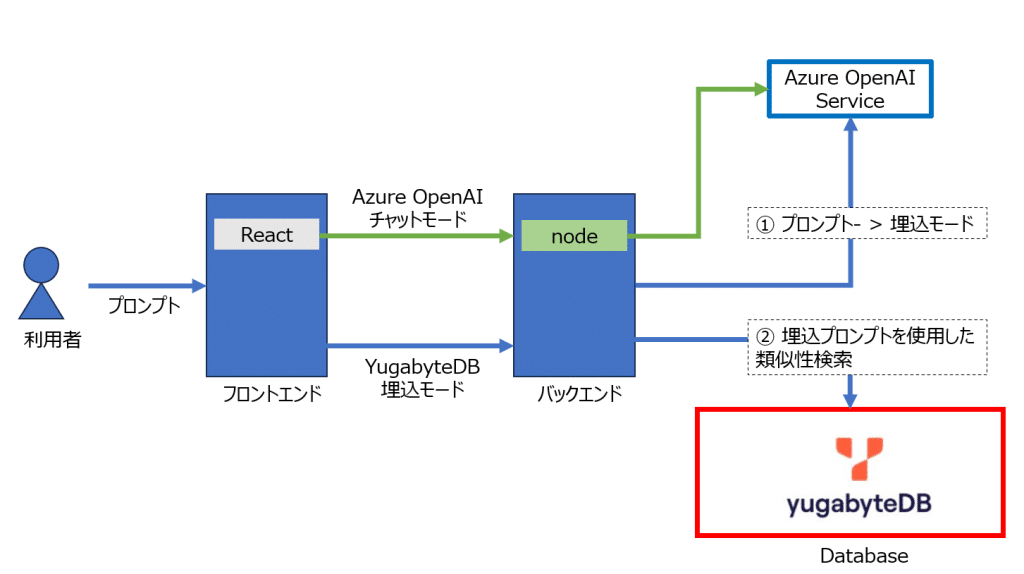
Azure OpenAI 固有の設定は Azure OpenAI Studio 管理「デプロイ」を使用します。
指定するデプロイ名GPTモデルは got-model, 埋込モデルは embeddings-model とします。
Azure OpenAI エンドポイントおよびキーの管理情報は Azure ポータルのリソースグループから参照します。

エンドポイントおよびキーの管理情報はリソースグループ内からご確認ください。
セットアップからチャットモード アプリケーションの起動まで順を追って解説
- Git から https://github.com/YugabyteDB-Samples/yugabytedb-azure-openai-lodging-service をローカル環境へクローンします。
- クローンしたパスを {project_dir} に読み替えて、バックエンドとフロントエンドそれぞれのパスを npm init します。
- {project_dir}/application.properties.ini ファイル内の AZURE_OPENAI_KEYとAZURE_OPENAI_ENDPOINTを前述した Azure OpenAI Studio と Azure リソースグループを参照し反映し、Azure OpenAIで指定したデプロイ名もこの ini ファイルへ反映します。
- 次に 3ノードYugabyteDBクラスタをDockerにデプロイし起動します。
Yugabyte ブログは Winodws 向けに書かれていないので複数行に分けて書くバックスラッシュ(\)はWindows ではエラーとなるので、キャレット(^)を使用します。 - 3ノードYugabyteDBクラスタを起動すると、Docker GUIのコンテナからも起動したことを確認できます。
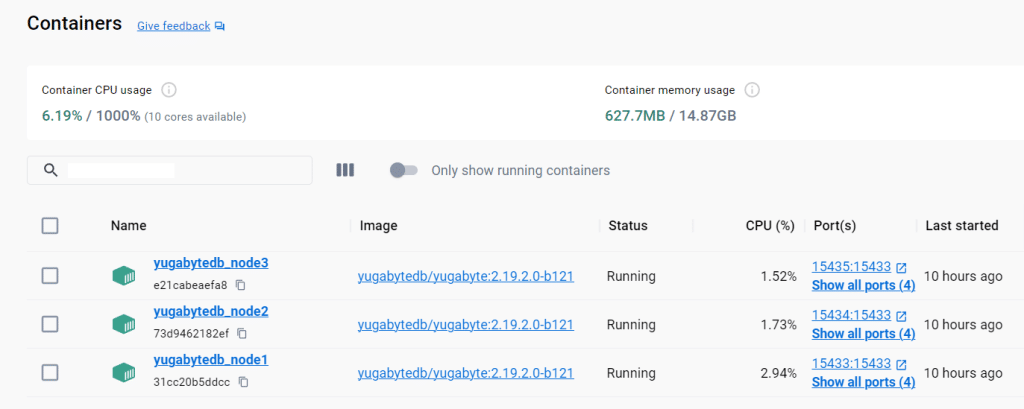
(Docker Desktop GUI | Containers 表示例)
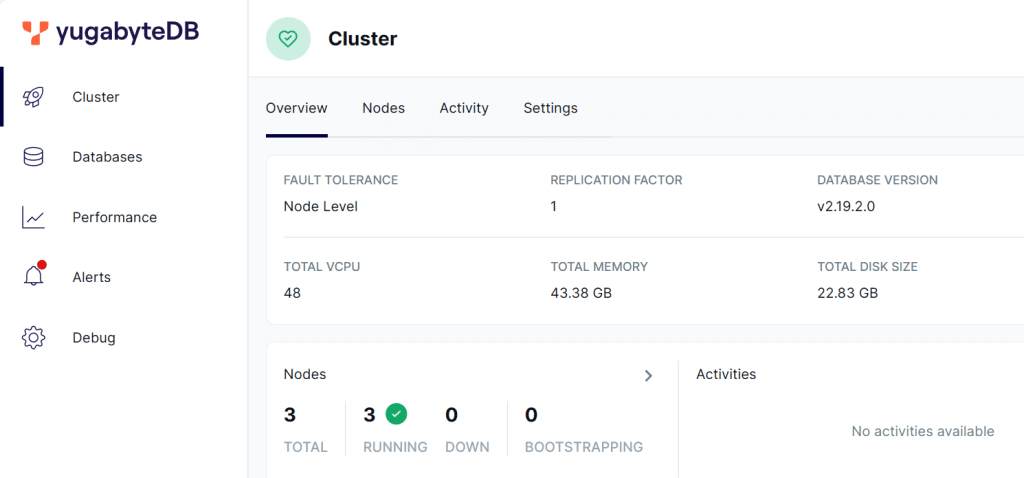
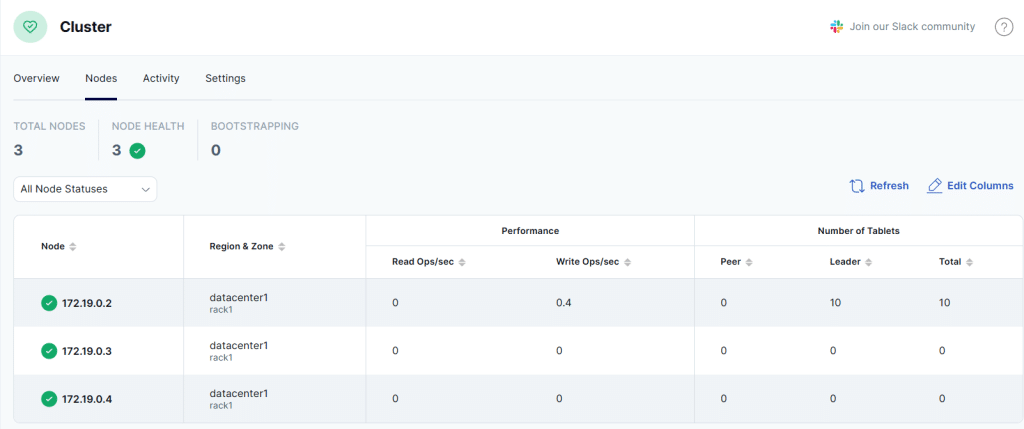
- YugabyteDB UI を開き、データベースが稼働していることを確認します。
http://127.0.0.1:15433 (環境によってはWindows ファイアウオールやセキュリティ アプリケーションが UI接続をブロックすることがあります。その場合は、システム管理者へご相談ください)
- Airbnbデータセットの読み込み
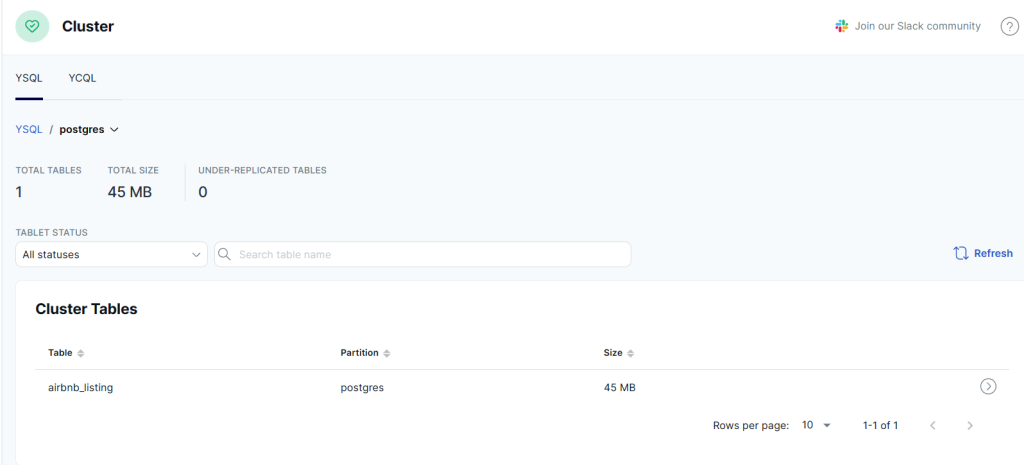
その前に、airbnb_listingテーブルをYugabyteDB上に作成し、{project_dir}\sql\sf_airbnb_listings.csv (34.1MB 構成データセット)を格納します。
この時、埋込モード用に pgvector 拡張を有効にするテーブル列を追加します。
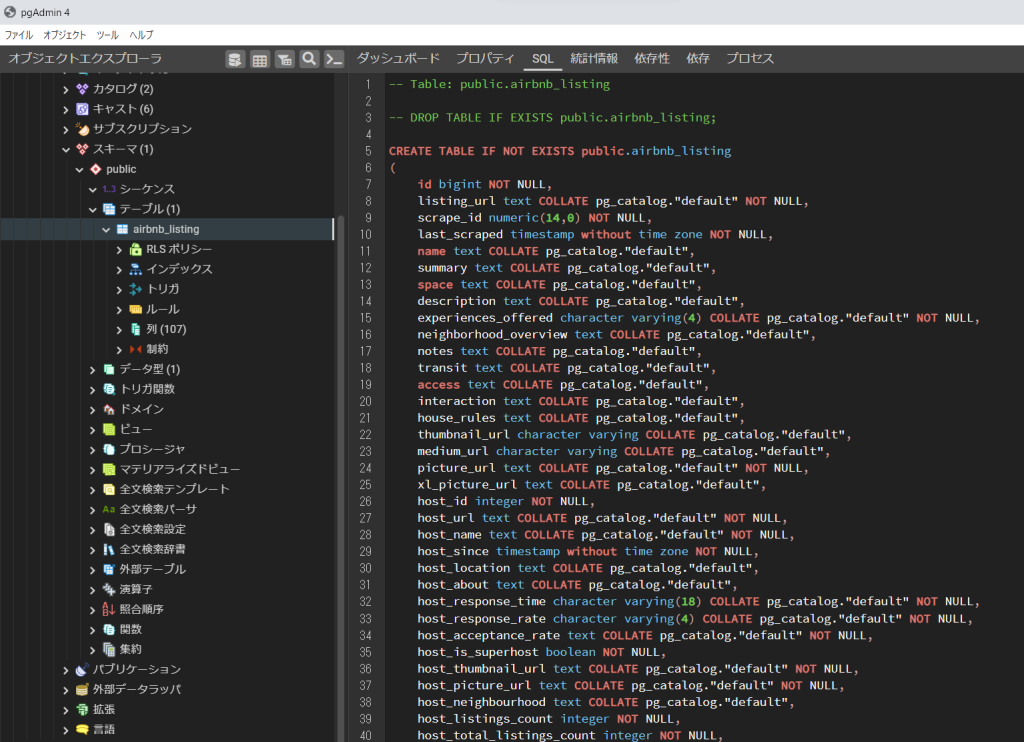
(テーブルが作成された内容を pgAdmin4 で参照した例:本記事以外のツール利用)
- Airbnbリスティングの埋込を生成します。
Airbnbのリスティングには、部屋数、アメニティの種類、場所、その他の機能など、詳細な宿泊施設の説明が掲載されています。その情報は説明列に保存され、ユーザープロンプトに対する類似性検索に最適です。ただし、類似検索を有効にするには、まず各説明をベクトル化された表現に変換する必要があります。
本記事のサンプルアプリケーションには、すべての Arbnb プロパティの説明の埋め込みを作成する埋込ジェネレーター ({project_dir}backend\embeddings_generator.js) が付属しています。
ジェネレーターは、登録情報の説明を読み取り、Azure OpenAI 埋め込みモデルを使用して説明ベクタを生成し、データベースの description_embedding 列に格納されます。
※3ノード構成YugabyteDBクラスタを動作させるDocker環境によりますが、埋込生成に要する時間は参考例としてCPU AMD Ryzen7 6800H, RAM 32GB, NVMe Gen.4, Windows 11 Pro (x64) で概ね 12分でした。
- チャットモード アプリケーションの起動
バックエンド、フロントエンドそれぞれを npm init で起動します。npm init 実行時、プリケーションパッケージに関する文字列入力が表示されますが、すべて[Enter] 押下で構いません。適切に init が終わると、package.json がカレントパスに生成されます。
さっそく、Webブラウザを起動してみましょう。 http://localhost:3000/
(アーキテクチャ図で示した通り、フロントエンドは Reactで記述されたコンテンツです)
- Azure OpenAI チャットモードでの類似性検索
アプリケーションの Azure OpenAI チャット モードは、Azure チャット入力候補 API に依存しています。このモードでは、アプリの動作は ChatGPT の動作と似ています。ほぼ同じ方法で操作できます。
プロンプトを入力すると、要求された情報を返すニューラルネットワークにそのまま送信されます。
たとえば、次のプロンプトを GPT モデルに送信して、いくつかの推奨事項を取得します。
素晴らしい港湾の景色を望むゴールデンゲートブリッジ近くのアパートを探しています。(和訳)
I’m looking for an apartment near the Golden Gate Bridge with a nice view of the Bay.
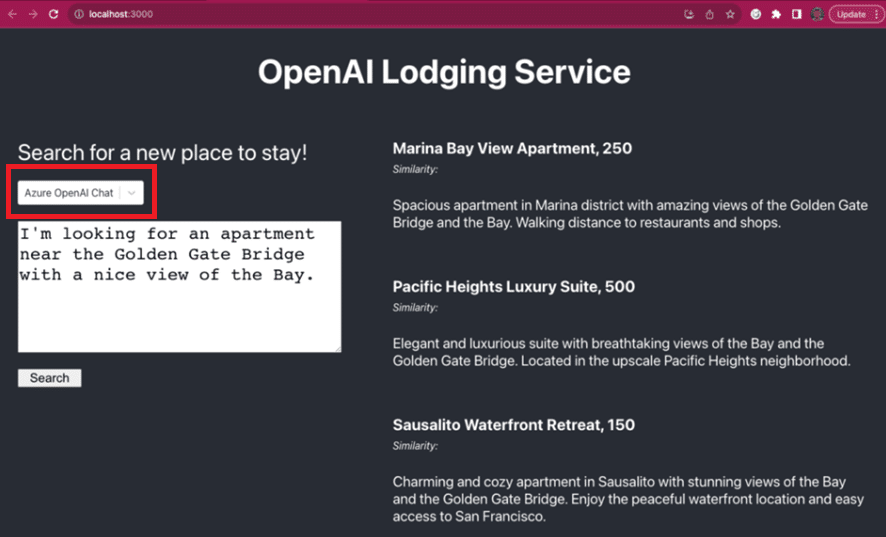
“Azure OpenAI Chat” がリスト選択されていることを確認し、
左側のプロンプトに英文で打鍵し [Search]クリックすると、右側に結果が表示されます。
(およそ5~20秒要します)
何故、北米西海岸ベイエリア限定なのでしょうか?
何故、提示は3案なのでしょうか?
何故、応答時間を要するのでしょうか?
その疑問や動作メカニズムについてはこの後にご説明いたします。
Azure OpenAIチャットモード アプリケーションの動作メカニズムについて{project_dir}backend\openai_chat_services.js から抜粋して解説
- ニューラルネットワーク用のシステムメッセージとユーザーメッセージを準備します。
システムメッセージは、GPTモデルに期待されることを明確にします。
ロール:system
コンテント:あなたはサンフランシスコでの宿泊施設を探すのに役立つアシスタントです。
3つの選択肢を提案します。 以下の形式で JSON オブジェクトを返送してください。
“[{\”name\”: \”<ホテル名>\”, \”description\”: \”<ホテルの説明>\”, \”price\”: <ホテルの料金>}]” +応答に他のテキストを追加しないでください。
※ここで3案を提示することと、北米西海岸サンフランシスコを指定しており「Azure OpenAI チャットモードでの類似性検索」回答がピンポイントのエリアだったのかの説明となります。

- 入力されたメッセージ(電文)は Azure OpenAI サービスに送信されます。

- アプリケーションは応答から推奨事項を含むJSONデータを抽出し、それらの結果をReactフロントエンドに返します。

選択したGPTモデルタイプ、Azureサブスクリプション、ニューラルネットワークのワークロードによっては、チャット入力候補APIがレコメンデーションを生成するまでに5秒から20秒かかる場合があります。
レコメンデーション取得のレイテンシが1秒未満になるように、ソリューションをスケーラブルにするには、アプリのYugabyteDB埋込みモードに切り替える必要があります。
YugabyteDB埋込モードによるスケーリング
アプリケーション UI から YugabyteDB Embeddings モードを選択し、同じプロンプト送信すると、
異なる候補のリストが表示されますが、待機時間は 1 秒未満です。
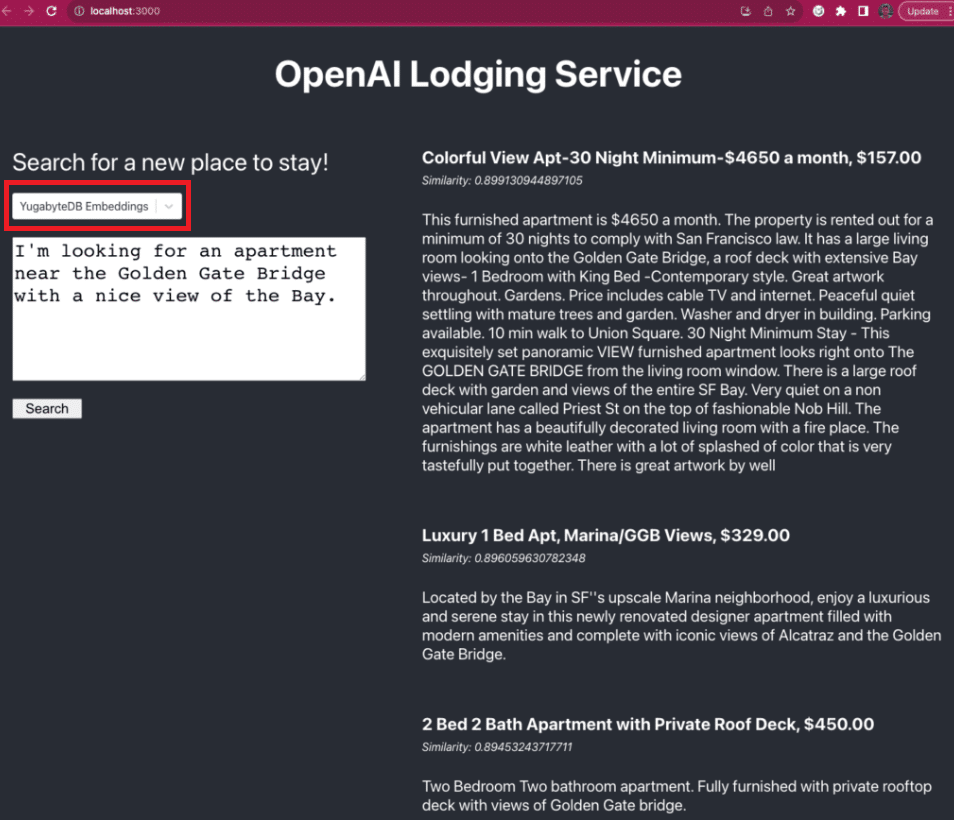
“YugabyteDB Embeddings” がリスト選択されていることを確認し、左側のプロンプトに英文で打鍵し [Search]クリックすると、右側に結果が表示されます(1秒以内に結果が出ます)。
このモードは、分散YugabyteDBクラスタに保存された独自のデータセットを介して類似検索が行われるため、パフォーマンスが向上します。
YugabyteDB埋込モード アプリケーションの動作メカニズムについて {project_dir}backend\yugabytedb_embeddings_service.js から抜粋して説明
- アプリケーションは、Azure OpenAI 埋込モデルを使用して、ユーザー プロンプトのベクトル化された表現を生成します。
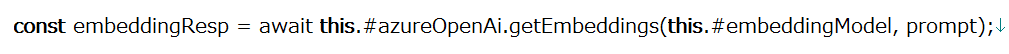
- アプリは、生成されたベクタを使用して、YugabyteDBに保存されている最も関連性の高いAirbnbプロパティを取得します。

類似度は、description_embedding列に格納された埋め込みとユーザー プロンプトのベクトル間の
コサイン距離(*)として計算されます。
(*)コサイン距離
距離とは2つ以上のデータが類似している度合いを、類似度の大きさや距離の近さとして数値化し表わすことです。AIに利用される機械学習済みモデルの多くはデータの類似性と距離を測定済みです。ここでコサイン距離とは、コサイン類似度と呼ばれることがありますが、類似度が1または-1に近いかによってプロンプト入力された文と回答文がポジティブとなるよう計算して提示する仕組みです。
- 提案されたAirbnbプロパティは、JSON形式でReactフロントエンドに返されます。

ここまでが、今回のハンズオンで自習する内容でした。
YugabyteDB Release 2.19 で拡張された新機能のうち代表的な5機能をご紹介
- PostgreSQL拡張機能(pgvector)を導入:
アプリケーションのベクトル類似性検索と埋め込みの保存が可能となりました。←本記事で扱う機能。 - PostgreSQLのようなトランザクションのセマンティクスに対応:
YugabyteDBはPostgreSQLとのランタイム互換性を常に提供してきましたが、現在ではKey分離機能のサポートを補完するために、ペシミスティックロック(*)によるリードコミット分離の強化を提供します。 - 簡素化されたディザスタ リカバリ (災害復旧機能)ワークフロー:
災害発生時にレプリカを昇格させたり、計画的なフェイルオーバーをはAPI(**)やコマンド (yb-admin)を介して定期的に実行したり、YugabyteDB (Webダッシュボード)ボタンをクリックするだけで実行できます。 - 簡素化されたOSSエクスペリエンス:
Yugabytedを使用して、グローバルアプリケーション向けに、あらゆるサイズのYugabyteDBクラスタをデプロイおよび運用します。
(*)ペシミスティックロック(Pessimistic Lock)
データベースや並行プログラムで複数のトランザクションが同じデータを同時に更新することを防ぐためのロックの一種です。ペシミスティックロックは、トランザクションがデータを読み取り、そのデータを変更しようとする前に、データをロックすることで競合を防ぐ目的で使用されます。
一方で、ペシミスティックロックの対照として、オプティミスティックロック(Optimistic Locking)というアプローチも存在します。オプティミスティックロックは、データを読み取る段階ではロックをかけず、データを実際に変更しようとするときに競合をチェックします。競合が検出された場合、トランザクションはロールバックされます。オプティミスティックロックは同時実行性を向上させますが、競合が発生する可能性があるため、データ整合性を確保するために注意が必要です。
適切なロック戦略は、特定のアプリケーションやデータベースの要件に応じて決定されるべきであり、ペシミスティックロックとオプティミスティックロックはそれぞれ異なる利点と制約を持っています。
(**) API は YugabyteDB YBA でご利用になれ、YugabyteDBをクラウド上で展開および運用するためのセルフマネージド型サービスです。また、YugabyteDBマネージド型マルチクラウドサービスとして Yugabyte AnyWhere があり導入は極めて迅速で Yugabyte サポート付きです。
TD SYNNEX 株式会社では YugabyteDB はもちろん、Microsoft Azure OpenAI サービスもお取り扱いしておりますので、ご興味のある方はお問い合わせフォームよりお気軽にご連絡ください。
また、YugabyteDBをさらにお知りになりたい方は、ぜひこちらのページに掲載している資料や動画もご参照ください。
[著者プロフィール]
TD SYNNEX 株式会社 | 斉藤 之雄
アドバンスドソリューション部門 ソリューションビジネス開発本部 プリセールス&エンジニアリング部 マルチクラウドチーム (Azure Solutions Architect Expert, Azure DevOps Engineer Expert)
マイコン少年時代から関東電子(TD SYNNEX前身)を利用するなどソフトウェア、ハードウェアともに昔をよく知る。コンピューター業界は1996年から異種混在環境における再販ビジネスの技術営業からキャリアを開始し、特に導入支援や教育プログラムの立ち上げは定評を有する。国内大手電気通信事業者では社内クラウドコミュニティの主要メンバーとし全国SEへ対するリスキリングプログラム推進活動を実践した。2022年4月TD SYNNEX入社以来、CoE(センターオブエクセレンス)プロダクトの日本市場展開や AI/ML (人工知能/機械学習)サービスを中心とするプリセールス活動を行っている。愛猫家、社会福祉士でもある。


