

日々進化する生成AIは、既に多くのビジネスシーンで活用されています。しかし、その法的リスクについては必ずしも正しく理解されておらず、特に著作権との関係では、知らず知らずのうちに著作権侵害の当事者になってしまう場合もあります。
そのような中、文化庁は、令和6年3月15日、「AIと著作権に関する考え方」(以下、単に「考え方」といいます。)を公表しました。そこで本記事では、「考え方」で示されたポイントを踏まえつつ、生成AIの仕組みや著作権法の基本的な考え方、活用上の注意点等について解説します。
生成AIとは

まずは簡単に、生成AIの概要と著作権との関係性について説明します。
従来のAIとの違い
従来のAIは、事前に学習した文章や画像等の特徴をもとに、条件に応じた回答を抽出・予測することが主な特徴であったのに対して、生成AIは、新たにコンテンツを生成することができる点で大きな違いがあります。生成できるコンテンツには様々なものがあり、文章や画像はもちろんのこと、最近では動画や音声、3Dモデルなど、様々なコンテンツを生成できるサービスが日々続々と登場しています。
生成AIの仕組みと著作権の関係性
しかし、生成AIが社会に普及するにつれて、様々な法的リスクが指摘されるようになり、特に著作権との関係については、様々な業界から多くの懸念の声が上がっています。そこでまずは、生成AIに関して、なぜここまで著作権が問題となるのかを簡単に解説します。
生成AIの仕組みは、簡単にいえば、事前に学習した膨大なデータをもとに、プロンプト(入力・指示)対して、確率論的に最も可能性の高い回答(コンテンツ)を出力・生成するものですが、その過程において、著作物が利用されうる場面には、大きく分けて、「開発・学習段階」と「生成・利用段階」という2つの段階があります。
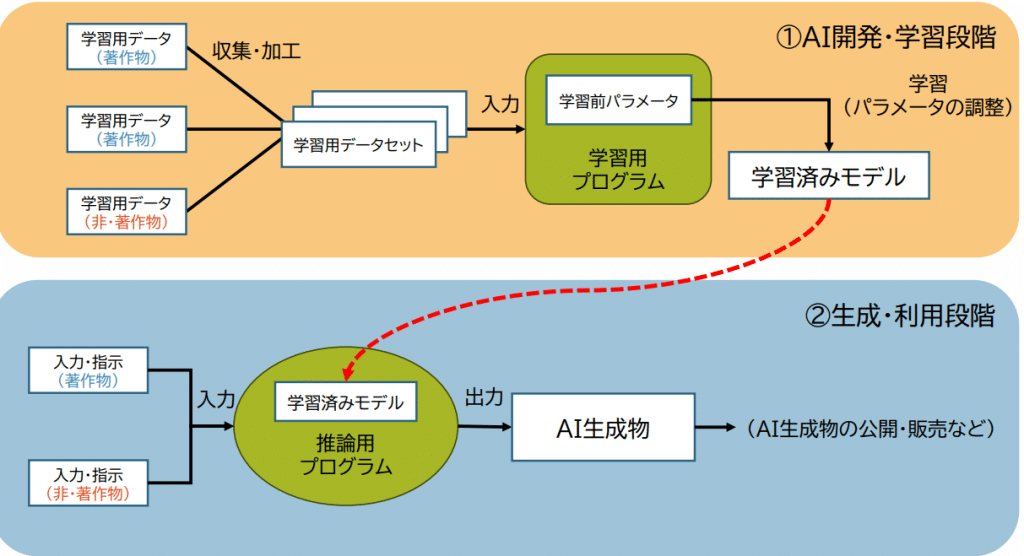
出典:文化庁著作権課「A I と著作権」より
1) 「開発・学習段階」は、主に生成AIを開発または提供する事業者が関係する段階です。AIに学習させるための学習用データを収集・加工する過程において、著作物を複製する必要があることから、著作権侵害の問題が生じてしまいます。
2)「生成・利用段階」は、主に生成AIの利用者が関係する段階であり、他者の著作物と類似するコンテンツを生成AIが生成してしまった場合などに著作権侵害の問題が生じます。また、生成・利用段階では、著作権侵害の問題に加えて、生成AIが生成したコンテンツ(以下、「AI生成物」といいます。)が、「著作物」に当たるのか、という問題もあります。
仮にAI生成物が著作物に当たらないとすれば、著作権の保護対象とならず、他社によるフリーライドを許してしまいかねないため、ビジネスにおいては致命的な問題です。
いずれの段階の問題であるかによって問題となる利用行為の種類や関係する著作権法の条文も異なってくるため、著作権法上の法的リスクを考える場合には、まず自分がどの段階にいるのかを把握することが重要となります。
著作権法の基本的な考え方
以上のように、生成AIに関する著作権法上のリスクには、様々な段階の問題があるため、著作権法の基本的な考え方についても、ここで簡単に解説しておきます。
著作物とは
著作権の保護対象である「著作物」とは、「思想又は感情を創作的に表現したものであつて、文芸、学術、美術又は音楽の範囲に属するもの」と定義されています。著作物に当たらなければ、そもそも著作権法の問題は生じないので、もっとも根本的な問題といえるでしょう。
ポイントは、「創作的」な「表現」という点です。そのため、単なるデータ(事実)やありふれた表現、表現には満たないアイデア(作風や画風などの抽象的な概念)は、著作物には該当しません(「表現・アイデア二分論」)。
著作権法の基本的なルール
著作物に当たる場合には、原則として、著作権者からの許諾を得なければ第三者は著作物を利用できない(許諾を得ないで著作物を利用すると原則として著作権侵害になる)、というのが著作権法の基本的なルールです。
権利制限について
著作権法は一定の場合には著作権を制限し、例外的に著作権者の許諾なく著作物を利用できる(著作権侵害にならない)場合を複数定めています(このような規定を「権利制限規定」といいます。)。
「私的使用」(30条)や「引用」(32条)などは、この権利制限規定の一部です。
そして、生成AIとの関係で特に重要な権利制限規定が、「著作物に表現された思想又は感情の享受を目的としない利用」(30条の4)という規定です。AI等の技術革新に伴い平成30年に追加された比較的新たな権利制限規定であり、「考え方」においても、どのような場合であれば生成AIの利用が権利制限規定の要件を満たす(=著作権侵害にならない)のか、という点に焦点が置かれています(詳細は後述)。
著作権侵害の要件
権利制限規定について簡単に解説しましたが、原則的に著作権侵害とならない場合であれば、そもそも権利制限規定を検討するまでもなく著作権侵害にはなりません。
著作権侵害の要件について、判例では、ある作品に、既存の著作物との➀類似性と➁依拠性の両方が認められる場合に、著作権侵害になるとされています。つまり、類似性か依拠性のいずれかが欠ければ、著作権侵害にはならないということです。
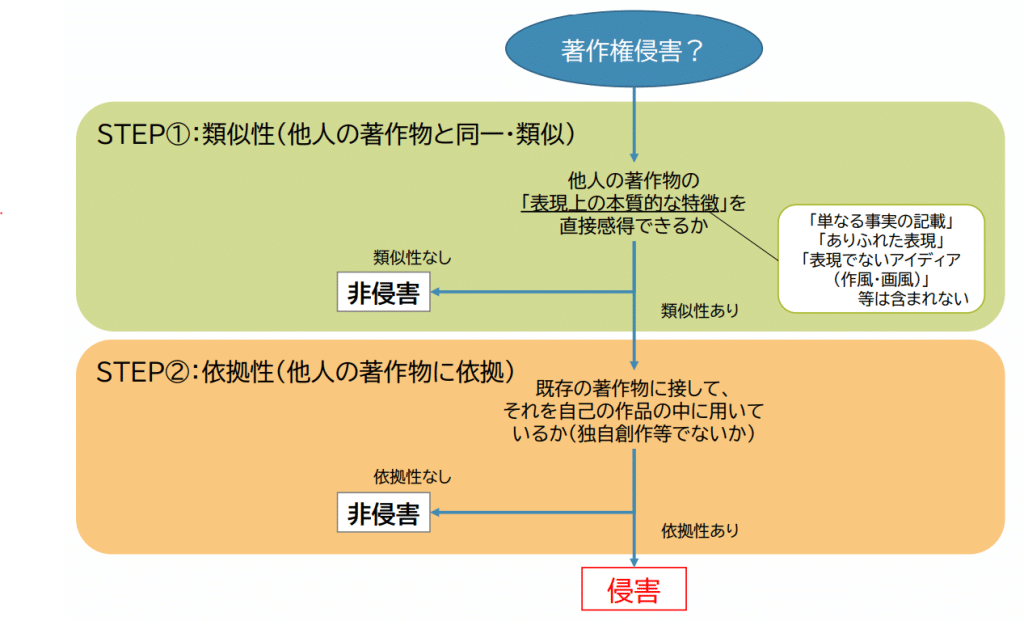
出典:文化庁著作権課「A I と著作権」より
文化庁が公表した「考え方」のポイント
文化庁が公表した「考え方」は、あくまで、文化庁の法制度小委員会が、様々な関係者にヒアリングをしたうえで1つの考え方を示したものに過ぎす、法的拘束力はありません。
したがって、実際に生成AIに関する著作権侵害の訴訟が提起された場合、裁判所が異なる解釈をする場合も十分にありえます。
とはいえ、裁判例の蓄積がない現状において、余計なコンフリクトを避けるためには、しばらくはこの「考え方」が重要な指標になるものと思われます。
重要なポイントは、以下の3点です。
- 開発・学習段階では30条の4の解釈が重要
- 生成・利用段階では依拠性の考え方が重要
- AI生成物の著作物性にも要注意
以下では、それぞれのポイントについて、詳しく解説します。
生成AIの開発・学習段階の著作権法上のリスク

前述したように、開発・学習段階では、学習用データセットを作成する過程で著作物を複製することがあるため、原則として著作権者の許諾を得る必要があります。しかし、膨大な学習用データのすべてについて許諾を得ることは現実的ではありません。そこで問題となるのが、30条の4という権利制限規定です。
(著作物に表現された思想又は感情の享受を目的としない利用)
第三十条の四 著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 (略)
二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合
三 (略)
「非享受目的」について
30条の4は、AI等の技術革新に柔軟に対応すべく新設された規定であり、「著作物に表現された思想又は感情の享受を目的としない」場合(非享受目的)には、著作権者の許諾なく著作物を利用できるとする規定です。
そして、AIに学習させることを目的として著作物を利用する場合は、「情報解析…の用に供する場合」として、非享受目的があるというのが前提です。
しかし、学習自体が非享受目的だとしても、学習後にそのまま出力させる目的がある場合、すなわち、非享受目的と享受目的が併存する場合にも、30条の4が適用されるのかという点が議論されていました。
この点について、「考え方」は、開発・学習段階で享受目的が1つでも併存する場合には30条の4は適用されない(著作権者の許諾なく利用できない)という見解を示しました。
また、享受目的が併存すると評価される場合について、以下のような具体例 も挙げられています。
• 既存の学習済みモデルに対する追加的な学習(そのために行う学習データの収集・加工を含む)のうち、意図的に、学習データに含まれる著作物の創作的表現の全部又は一部を出力させることを目的とした追加的な学習を行うため、著作物の複製等を行う場合
(例)AI 開発事業者又はAI サービス提供事業者が、AI 学習に際して、いわゆる「過学習」(overfitting)を意図的に行う場合
• 既存のデータベースやインターネット上に掲載されたデータに含まれる著作物の創作的表現の全部又は一部を、生成 AI を用いて出力させることを目的として、これに用いるため著作物の内容をベクトルに変換したデータベースを作成する等の、著作物の複製等を行う場合
「著作権者の利益を不当に害することとなる場合」について
非享受目的の場合であっても、例外として「著作権者の利益を不当に害することとなる場合」には30条の4は適用されません。とはいえ、どのような場合に「著作権者の利益を不当に害することとなる」のかという点が議論されてきました。
この点について、「考え方」は、主に3つの場合を念頭に、以下のような見解 を示しました。
1) 著作権法が保護する利益でないアイデア等が類似するにとどまるものが大量に生成されることにより、特定のクリエイター又は著作物に対する需要が、AI 生成物によって代替されてしまうような事態が生じることは想定しうるものの、当該生成物が学習元著作物の創作的表現と共通しない場合には、著作権法上の「著作権者の利益を不当に害することとなる場合」には該当しない
2) 大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物が販売されている場合に,当該データベースを情報解析目的で複製等する行為が「著作権者の利益を不当に害することとなる場合」に該当するところ、その具体例としては、インターネット上のウェブサイトで、ユーザーの閲覧に供するため記事等が提供されているのに加え、データベースの著作物から容易に情報解析に活用できる形で整理されたデータを取得できるAPIが有償で提供されている場合において、当該APIを有償で利用することなく、当該ウェブサイトに閲覧用に掲載された記事等のデータから、当該データベースの著作物の創作的表現が認められる一定の情報のまとまりを情報解析目的で複製する行為がこれに該当しうる
3) AI 学習のための著作物の複製等を防止する技術的な措置が講じられており、かつ、このような措置が講じられていることや、過去の実績(情報解析に活用できる形で整理したデータベースの著作物の作成実績や、そのライセンス取引に関する実績等)といった事実から、当該ウェブサイト内のデータを含み、情報解析に活用できる形で整理したデータベースの著作物が将来販売される予定があることが推認される場合には、この措置を回避して、クローラにより当該ウェブサイト内に掲載されている多数のデータを収集することにより、AI 学習のために当該データベースの著作物の複製等をする行為は、当該データベースの著作物の将来における潜在的販路を阻害する行為としてこれに該当しうる
生成AIの生成・利用段階の著作権法上のリスク

依拠性の考え方
生成・利用段階では、前述したように、他者の著作物と類似するコンテンツを生成AIが生成してしまった場合などに著作権侵害の問題が生じます。
著作権侵害の有無は、類似性と依拠性により判断されますが、生成AIにおいて特に問題となるのが依拠性です。
生成AIは、プロンプトに対して確率的にもっとも可能性の高いコンテンツを生成しているだけであり、また、どのような推論を経て生成AIがコンテンツを生成しているのかは事後的な検証が不可能であるという理由から、依拠性の有無が判断しづらいとされてきたのです。
この点に関して、「考え方」は、AI利用者が既存の著作物を認識していたか否かに場合分けして、以下のように見解を整理しました。
【AI利用者が既存の著作物を認識していた場合】
• 生成AI利用した場合であっても、AI 利用者が既存の著作物(その表現内容)を認識しており、生成AIを利用して当該著作物の創作的表現を有するものを生成させた場合は、依拠性が認められ、AI利用者による著作権侵害が成立すると考えられる。
(例)Image to Image(画像を生成 AI に指示として入力し、生成物として画像を得る行為) のように、既存の著作物そのものを入力する場合や、既存の 著作物の題号などの特定の固有名詞を入力する場合
• 既存の判例・裁判例を踏まえると、生成AIが利用された場合であっても、権利者としては、被疑侵害者において既存著作物へのアクセス可能性があったことや、生成物に既存著作物との高度な類似性があること等を立証すれば、依拠性があるとの推認を得ることができると考えられる。
【AI利用者が既存の著作物を認識していなかった場合 】
• AI 利用者が既存の著作物(その表現内容)を認識していなかったが、当該生成AIの開発・学習段階で当該著作物を学習していた場合については、客観的に当該著作物へのアクセスがあったと認められることから、当該生成AIを利用し、当該著作物に類似した生成物が生成された場合は、通常、依拠性があったと推認され、AI利用者による著作権侵害になりうると考えられる。
• ただし、当該生成AIについて、開発・学習段階において学習に用いられた著作物の創作的表現が、生成・利用段階において生成されることはないといえるような状態が技術的に担保されているといえる場合もあり得る。このような状態が技術的に担保されていること等の事情から、当該生成 AIにおいて、学習に用いられた著作物の創作的表現が、生成・利用段階において出力される状態となっていないと法的に評価できる場合には、AI利用者において当該評価を基礎づける事情を主張することにより、当該生成AIの開発・学習段階で既存の著作物を学習していた場合であっても、依拠性がないと判断される場合はあり得ると考えられる。
【AI利用者が既存の著作物を認識しておらず、かつ、AI 学習用データに当該著作物が含まれない場合】
AI利用者が既存の著作物(その表現内容)を認識しておらず、かつ、当該生成AIの開発・学習段階で、当該著作物を学習していなかった場合は、当該生成AIを利用し、当該著作物に類似した生成物が生成されたとしても、これは偶然の一致に過ぎないものとして、依拠性は認められず、著作権侵害は成立しないと考えられる。
AI生成物の著作物性
前述のように、生成・利用段階では、AI生成物が‘著作物に該当するのか、という問題もあります。この点に関して「考え方」は、以下のような見解 を示しています。
AI 生成物の著作物性は、個々の AI 生成物について個別具体的な事例に応じて 判断されるものであり、単なる労力にとどまらず、創作的寄与があるといえるものがどの程度積み重なっているか等を総合的に考慮して判断されるものと考えられる。
例として、 著作物性を判断するに当たっては、以下の1~3に示すような要素があると考えられる。
- 指示・入力(プロンプト等)の分量・内容
- 生成の試行回数
- 複数の生成物からの選択
また、人間が、AI生成物に、創作的表現といえる加筆・修正を加えた部分については、通常、著作物性が認められると考えられる。もっとも、それ以外の部分についての著作物性には影響しないと考えられる。
具体的に著作権侵害となるケースは?
「考え方」を基準にした場合に、著作権侵害となるか否か、以下生成AIを利用する際の具体的なケースを考えてみましょう。
Webから他者の制作物を取得して生成AIの学習データとして利用した
他者の著作物を学習データに利用する場合、通常その過程において、著作物を複製する必要があることから、著作権者の許諾なく学習データとして利用すれば著作権侵害となります。
もっとも、30条の4の「情報解析…の用に供する場合」として非享受目的が認められれば、著作権者の許諾がなく利用しても著作権侵害にはなりません。
ただしこの場合でも、学習段階において、当該著作物をそのまま出力させる目的を有していれば、享受目的が併存するものとして30条の4は適用されず、著作権侵害となる可能性があります。
生成AIで作成した成果物が、他者の既存の作品と類似していたが、商用利用した
著作権侵害になるか否かは、類似性と依拠性により判断されます。類似性が認められることを前提とすると、問題となるのは依拠性です。そして、依拠性が認められるか否かは、当AI利用者が当該著作物を認識していたか否かが重要な判断要素となります。
例えば、当該著作物をプロンプトに入力していた場合や、実際に認識していなくとも当該著作物が学習用データに含まれていた場合には、依拠性があるものと推認されます。
ただし、このような場合でも、学習に用いられた著作物の創作的表現が、生成・利用段階において出力されることがないような状態が技術的に担保されている場合には、依拠性がないものと判断される可能性もあります。
生成AIで作成した画像を自社商品のパッケージに利用して販売した
当該画像に、他者の著作物との類似性または依拠性が認められなければ、著作権侵害の問題は生じません。ただし、当該画像に著作物性が認められなければ、著作権法の保護対象とならない点で、他社によるフリーライドや模倣に対して権利主張ができないなど別の問題が生じえます。
AI生成物に著作物性が認められるか否かは、プロンプトの分量や内容、生成の試行回数、人間による創作的表現といえる加筆・修正の有無等によって判断されることになります。
著作権侵害のリスクを理解して生成AIを活用するには?

まずは、自社が「開発・学習段階」と「生成・利用段階」のいずれで生成AIを活用しようとしているのかを把握し、法的リスクを正しく理解することが重要です。
また、生成AIの導入を検討する企業においては、従業員に対する利用上のルール設定や周知、研修等の措置を実施することも重要なリスクヘッジとなるでしょう。
多角的な視点で生成AIの活用を
以上、生成AIを活用するうえで知っておくべき生成AIの仕組みや著作権法の基本的な考え方から、生成AIと著作権に関して文化庁が公表した「考え方」のポイントを解説しました。もっとも、「考え方」に法的拘束力はなく、また、今後の議論次第では、考え方が変更される可能性もあります。
重要なのは、生成AIを活用すること自体を目的とするのではなく、あくまで課題解決のための1つの手段として、多角的な視点で活用方法を検討することでしょう。
【著者プロフィール】
河瀬季/かわせ・とき
モノリス法律事務所 代表弁護士
小3でプログラミングを始め、19歳よりIT事業を開始。
ベンチャー経営を経て、東京大学法科大学院に入学し、弁護士に。
モノリス法律事務所を設立し、ITへの知見を活かして、IT・ベンチャー企業を中心に累計1,075社をクライアントとしている。


